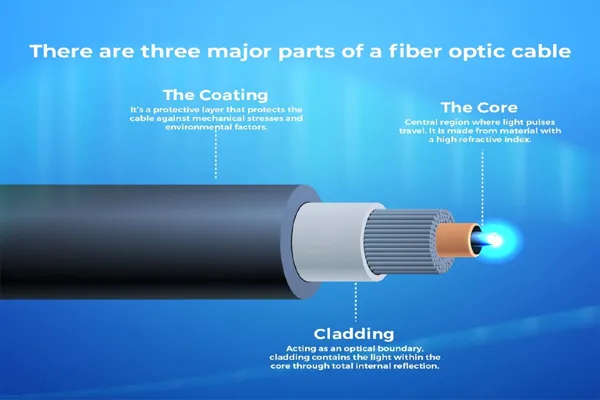
Google crawls websites using an automated program called Googlebot, also known as a web crawler or spider. The process begins when Googlebot visits a webpage, starting with a list of URLs from previous crawls, sitemaps submitted by website owners, or links discovered on other pages.
- Discovery: Googlebot identifies URLs to crawl. This can happen through links on other websites, sitemaps provided via Google Search Console, or manually submitted URLs.
- Crawling: Googlebot requests the webpage from the server and downloads its content, including HTML, CSS, JavaScript, and other resources. It follows a "crawl budget," prioritizing sites based on factors like update frequency, importance, and server response time.
- Rendering: For dynamic or JavaScript-heavy sites, Googlebot may render the page (similar to how a browser loads it) to fully understand the content and structure, including elements loaded after the initial HTML.
- Following Links: Googlebot scans the page for hyperlinks and adds them to its crawl queue, systematically exploring the web by following these connections.
- Indexing: After crawling, Google processes and stores the content in its index—a massive database—analyzing text, images, and other elements to determine relevance and context for search queries.
- Re-crawling: Googlebot periodically revisits pages to check for updates or changes, with frequency depending on the site’s activity and authority.
Website owners can influence crawling by optimizing site speed, using a clear structure with internal links, submitting an XML sitemap, and managing crawl directives (like robots.txt or "noindex" tags) to guide Googlebot efficiently.
This process ensures Google keeps its search results fresh and relevant.